
El idioma es uno de los aspectos de la cultura humana que más nos conciernen. Lo utilizamos a diario y dependemos de él para prácticamente todas nuestras comunicaciones con otras personas. De nuestra manera, somos todos expertos usuarios del lenguaje.
No hace falta ser un especialista en la lingüística (la ciencia que estudia el lenguaje) para saber que los idiomas cambian. A lo largo de las generaciones aparecen palabras y expresiones nuevas, se modifican las maneras en las cuales se pronuncian y escriben palabras, mientras que otras palabras y expresiones caen en desuso y desaparecen. Inclusive pueden cambiar las reglas gramaticales y de sintaxis, o sea las que definen cómo se unen las palabras para formar frases. El idioma de nuestros abuelos era distinto al nuestro, y cuanto más regresemos en el tiempo, más diferencias encontramos. Mientras que el Quijote de Cervantes alababa la “fermosura de la sin par Dulcinea”, un joven actual utilizaría probablemente otros términos para describir a su amada. Asimismo, cuesta leer las obras de teatro de Shakespeare o la Divina Comedia de Dante Alighieri. Los idiomas cambian, y sin duda hay razón para afirmar que ocurre un proceso evolutivo, parecido a la evolución de los seres vivos que pueblan la faz de la tierra; y mientras que las especies evolucionan por un proceso de selección natural, los idiomas lo hacen por selección cultural (o sociocultural, si se quiere).
Todo cambia – pero el idioma por encima de todo
En los últimos posts hemos hablado ya de la evolución cultural. Sigamos hoy con este tema, considerando la evolución de un importante aspecto de la cultura humana: el idioma. (Estaré utilizando principalmente el término idioma para referirme a los sistemas de comunicación verbal; otros prefieren la palabra lengua, y para referirse a la comunicación verbal en general, se puede utilizar también el término lenguaje.) Del origen del lenguaje hablamos ya en una oportunidad anterior (ver mi post del 19 mayo 2015). Veamos ahora cómo cambian los idiomas.
Los paralelos entre la evolución biológica y la lingüística son bastante profundos. Lo que en la naturaleza son las especies, los géneros y las familias, lo son en la lingüística los idiomas y las familias de idiomas. Los idiomas descienden de lenguajes anteriores, los llamados proto-idiomas, así como las especies descienden de sus especies antecesoras. Mientras que las especies cambian por mutaciones genéticas, los idiomas lo hacen por innovaciones lingüísticas. Así como hay extinción de especies, pueden desaparecer los idiomas; pero ambos pueden dejar sus rastros: las especies desaparecidas se pueden conocer mediante fósiles o restos en el ADN en las especies descendientes, y los idiomas muertos a través de textos antiguos o palabras en los idiomas posteriores. Y así hay unos paralelos más[1].
Familias de idiomas
Pero empecemos por el inicio: con el propio idioma. A veces es fácil distinguir un idioma de otro: por ejemplo, el chino del italiano. Otros idiomas son muy parecidos entre sí, tales como el danés y el noruego, o – como no – el castellano y el catalán; pero pueden ser considerados idiomas distintos por tener diferencias no sólo en las palabras, sino también en ciertas reglas gramaticales.
Si consideramos que los idiomas evolucionan, así como evolucionan las especies biológicas, podemos utilizar el grado de semejanza entre los idiomas para decir algo sobre sus relaciones y su historia. Podemos utilizar el mismo razonamiento que expuse en mi post del 30 marzo 2015 para las relaciones entre especies biológicas, aplicándolo ahora a los idiomas. Básicamente, podemos afirmar que los idiomas que se parecen mucho, tienen un ancestro común que existió en un pasado reciente, mientras que dos idiomas que se parecen poco, tienen un ancestro común que se habló en una época más remota – o inclusive, pudieran carecer de ancestro común. Veamos el siguiente ejemplo, inspirado en un ejercicio llevado a cabo por el erudito francés Joseph Justus Scaliger (1540-1609), el primero en agrupar los idiomas[2].
Consideremos la palabra “Dios” (en referencia específicamente al Dios cristiano) en distintos idiomas europeos: en italiano es Dio, en portugués Deus, en rumano Zeu (o Dumnezeu); en euskera (vasco) Jainko o Jaungoiko, en inglés God, en alemán Gott, en noruego Gud, en finés Jumala; en polaco es Bóg, en ruso Bog, y en serbio también; en húngaro Isten, y en griego Theos.
Basándonos en estas versiones del concepto “Dios”, vemos que podemos agrupar los idiomas mencionados en tres grupos, con algunos idiomas que no entran en ninguno de estos grupos:
- Castellano, italiano, portugués, y rumano. Estos idiomas mediterráneos (ver mapa) pertenecen a la familia de idiomas románicos. (El griego, juzgando esta sola palabra, pareciera estar relacionado con estos idiomas.)
- Inglés, alemán, y noruego. Estos idiomas del norte de Europa forman parte de la familia de los idiomas germánicos.
- Polaco, ruso, y serbio. Estos son algunos miembros de la familia de los idiomas eslavos, hablados en la Europa del Este.
- Los idiomas mencionados que no entran en ninguno de estos grupos son, obviamente, el vasco, el finés y el húngaro. Mientras que el vasco es un idioma único, el finés y el húngaro pertenecen ambos – aunque no se diría juzgando sus palabras por “Dios” – al grupo de los idiomas urálicos.
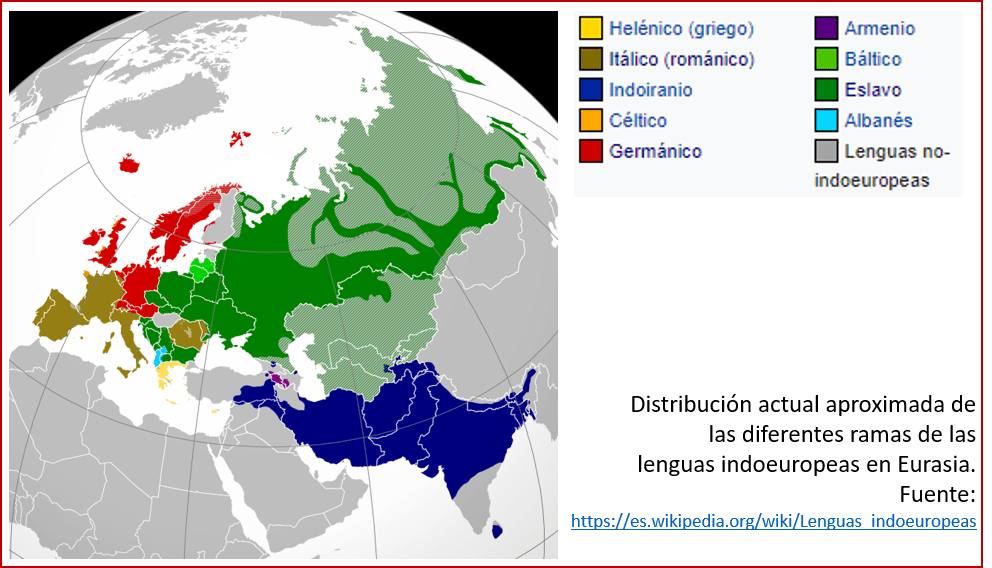
De esta manera hemos encontrado las tres familias de idiomas que dominan el mapa lingüístico europeo: los idiomas románicos, germánicos, y los eslavos. Los idiomas románicos son muy parecidos entre sí, mientras que al comparar un idioma de una familia con uno de otra familia, la semejanza ya no es tan grande. Esto nos indica que los idiomas románicos tienen un idioma ancestral común, los idiomas eslavos también (pero distinto al idioma ancestral románico), y lo mismo aplica a los idiomas germánicos, cuyo idioma ancestral es distinto al idioma ancestral románico y el ancestro del eslavo.
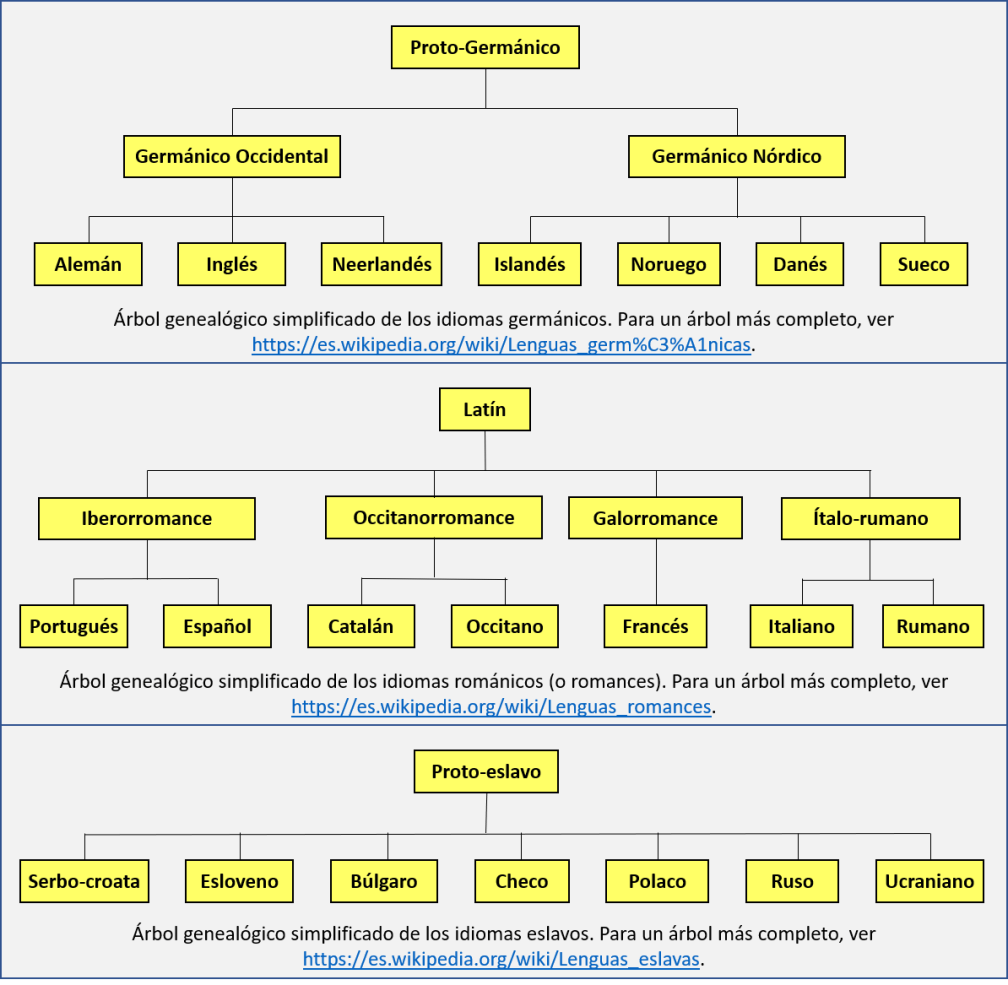
¿Cuáles pueden haber sido estos idiomas ancestrales? Sólo en el caso de los idiomas románicos lo conocemos: es el latín. Desconocemos cuáles son los idiomas ancestrales de la familia germánica y la eslava: quienes hablaron estos idiomas ancestrales no dejaron textos que podamos estudiar. Por lo tanto, llamamos al idioma ancestral germánico el “proto-germánico”, mientras que el “proto-eslavo” es el nombre con el que se denomina el idioma ancestral de los idiomas eslavos.
Así como se puede elaborar árboles genealógicos para las especies biológicas, también es posible elaborarlos para los idiomas, mostrando cómo se agrupan y de qué idioma ancestral provienen. En la figura se muestran árboles genealógicos simplificados para los idiomas germánicos, románicos y eslavos.
Obviamente no tiene mucho sentido científico basar una comparación de idiomas en una sola palabra. De hecho, lo normal es utilizar listas de centenares de palabras, tal como la lista de Swadesh (un lingüista de los años ’60) que consiste en 200 palabras básicas que ocurren en prácticamente todos los idiomas[3]. Sin embargo, sigamos pecando y veamos otro ejemplo, esta vez basado en dos palabras, “padre” y “madre”[4].
En italiano, “padre/madre” es también padre/madre, en portugués pai/mãe, en rumano tata/mama; en vasco aita/ama, en inglés father/mother, en alemán Vater/Mutter, y en noruego far/mor; en polaco es ojciec/matka, en ruso otets/mat, y en serbio otac/mati (o majka); y en griego moderno es pateras/mitera. A esta lista podemos añadir algunos idiomas antiguos, que ahora ya no se hablan más: el latín (pater/mater), el griego antiguo (patèr/mètèr) y el sánscrito, que se hablaba en la India (pitar/matar).
De una vez notamos que ya no hay tanta variación entre los distintos idiomas, especialmente si consideramos la palabra “madre”. En el caso de “padre”, notamos que hay un cambio de consonante entre los idiomas latinos y los germánicos: de “pater” a “father”; este cambio es bastante común y, por haber sido descrito por primera vez por uno de los hermanos Grimm (Jacob Grimm; 1785-1863), se le conoce ahora como la “Ley de Grimm”. En los idiomas eslavos, la palabra “padre” tiene obviamente un origen distinto a la de los otros idiomas bajo consideración.
La semejanza entre todos los idiomas mencionados, con la excepción de los idiomas distintos, tales como el vasco y el húngaro, conllevó a la agrupación de los mismos en un gran grupo, extendido por grandes partes de Eurasia (ver el mapa arriba): el de los idiomas indoeuropeos. Se supone que, en algún momento del pasado, existió un idioma, que ahora se está llamando el proto-indoeuropeo por falta de un nombre mejor, del cual descendieron las familias de los idiomas indoeuropeos actuales. En la figura abajo se muestra un árbol filogenético (un tipo de árbol genealógico que agrupa los idiomas en función de su semejanza) de los idiomas indoeuropeos. En varios artículos se encuentran árboles mucho más completos[5].
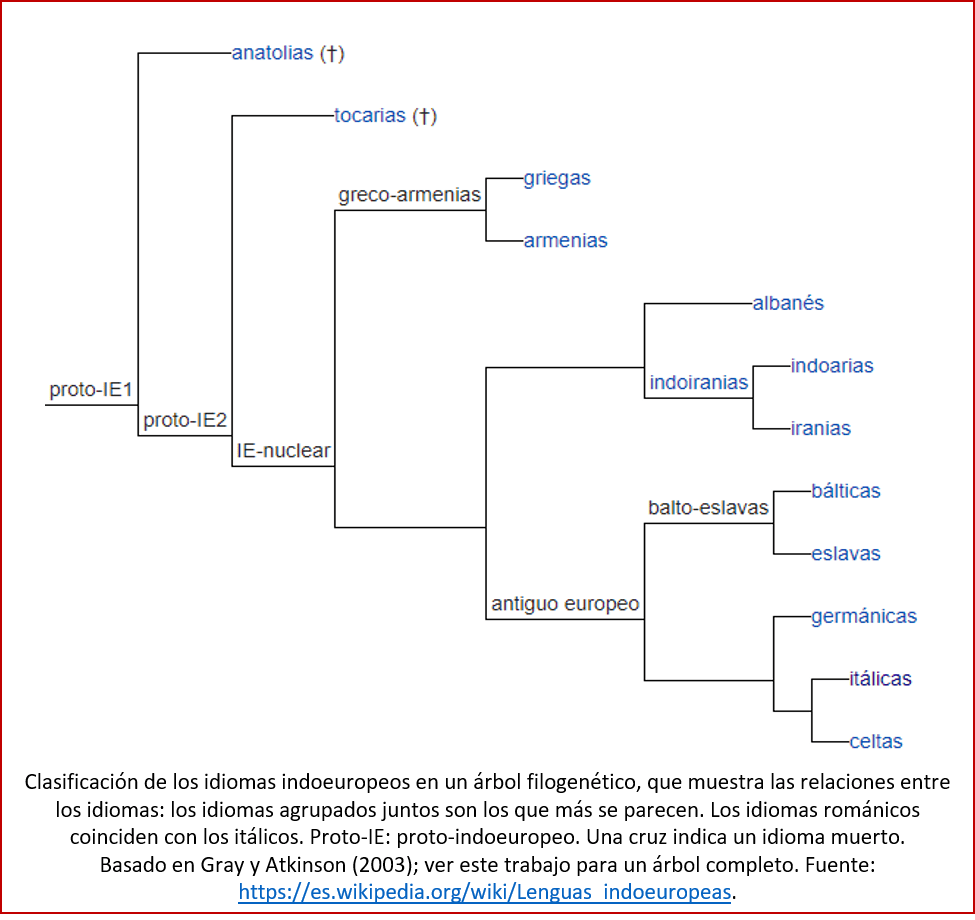
Ha sido posible reconstruir en cierta medida el proto-indoeuropeo. Pero todavía no se sabe con certeza dónde se habló, y cuándo. Tanto la lingüística, la arqueología como la genética apuntan a un origen en las estepas de Ucrania y el sur de Rusia, alrededor de 4000-3000 años a.C., donde la cultura Yamnaya inventó la rueda y se expandió – llevándose su idioma – por Europa y partes de Asia[6]. Pero ciertos estudios lingüísticos que trazan las diferencias entre los idiomas de la misma manera que los biólogos utilizan diferencias genéticas para aclarar las relaciones entre especies y poblaciones, sugieren que el indoeuropeo surgió antes, hace unos 8000-6000 años, en Anatolia (parte de la actual Turquía), y que los primeros agricultores que de Anatolia se extendieron por Europa introdujeron también el indoeuropeo[7]. La última palabra en esta discusión aun no ha sido hablada[8].
¿Termina aquí la historia? ¿Qué ocurre con el vasco y los demás idiomas del planeta? ¿Pueden algunos de estos idiomas ser agrupados con los idiomas indoeuropeos? Algunos piensan que sí, pero ya se está llegando al límite de lo que se puede determinar con los actuales métodos lingüísticos. Algunos lingüistas han propuesto agrupar el indoeuropeo con idiomas del norte de África, de la India y de la Rusia en una super-familia denominada “nostrática” [9]. Otros lo están agrupando con idiomas asiáticos centro-orientales, incluyendo el coreano, el japonés, e idiomas siberianos y del ártico americano, en otra super-familia, denominada “eurasiática”[10]. Posiblemente sabremos más acerca de esto en el futuro, pero por ahora se mantienen las incertidumbres al respecto de este asunto.
Árbol gramatical
Cabe destacar que no es sólo comparando palabras que se puede construir el árbol genealógico de los idiomas. También es posible utilizar aspectos gramaticales. Se ha planteado que el uso de aspectos gramaticales para elaborar un árbol genealógico de idiomas tiene como ventaja que se puede ir más hacia atrás en el tiempo: hasta más de 8000 años a.C., o inclusive hasta más de 10.000 años a.C.[11], mientras que comparando palabras se puede llegar a “sólo” unos 6000 años a.C. [12]. Sin embargo, estudios recientes muestran que esto es válido sólo para algunos aspectos gramaticales (por ejemplo la distinción de género para la tercera persona – “él” y “ella”), mientras que muchos otros aspectos gramaticales cambian inclusive más rápidamente que las palabras[13].
Diversificación de los idiomas
El árbol de los idiomas nos muestra la facilidad con la que se diversifican los idiomas: un proto-idioma suele dar origen a múltiples idiomas de manera que cada área geográfica va a tener su propio idioma. Pero, si la finalidad del idioma es la comunicación, ¿por qué se da esta diversificación, que resulta en una inhabilidad de poblaciones de entenderse mutuamente, al tener idiomas distintos?
Según una teoría, aceptada por muchos lingüistas, el lenguaje se desarrolló como una herramienta no solamente para intercambiar información, sino también para fomentar la vinculación entre individuos en un grupo. Esta última finalidad del lenguaje es también la causa de la diversificación de los idiomas: la identidad de una población se fortalece cuando tiene su propio idioma, distinto al de las poblaciones en su alrededor. De esta manera, el idioma o dialecto propio de una población sirve para diferenciarla: la manera de hablar de un individuo es su prueba de pertenencia a su comunidad[14].
Otra teoría explica la diversificación de los idiomas como un producto de deriva. El proceso de deriva implica cambios en la frecuencia de uso de ciertas variantes lingüísticas, que son pequeños y reversibles (o sea, neutros), pero que al acumularse pueden resultar en cambios irreversibles. De esta manera, por ejemplo, las palabras pueden cambiar de significado: la palabra inglesa clean (limpio) y la alemana klein (pequeño) tienen el mismo origen, pero hubo una divergencia debido a un proceso de deriva, mediante el que ocurrió una concatenación de pequeños cambios de significado. Según este enfoque, la diversificación de idiomas puede ser el resultado lógico de un proceso de deriva, y no haría falta recurrir a explicaciones sociales[15].
Las edades de los idiomas
Es imposible determinar con seguridad cómo fueron aquellos idiomas ancestrales (o sea, los proto-idiomas) de los idiomas actuales que no dejaron textos escritos (aunque se ha hecho reconstrucciones tentativas del indoeuropeo[16], y hasta se ha grabado textos en este proto-idioma reconstruido[17]). Lo que sí se ha podido hacer, es estimar cuándo se hablaron. Esto es el terreno de la glotocronología. Esta rama de la lingüística se dedica a realizar comparaciones cuantitativas entre las palabras de los idiomas y a estimar las tasas de cambio de las palabras a lo largo del tiempo. Al tener esta información, se puede deducir cuando dos idiomas se separaron: dos idiomas que tienen muchas palabras en común (es decir, cuyas palabras tienden a parecerse), se separaron hace relativamente poco tiempo, mientras que dos idiomas cuyos léxicos son muy distintos, se separaron hace mucho tiempo. Esto es análogo al cálculo de cuándo se separaron dos especies biológicas, basado en una comparación de, por ejemplo, su material genético[18]. El gran problema con el que ha tenido que lidiar la glotocronología, es que es difícil determinar la tasa de cambio de las palabras de los idiomas (se está utilizando como regla general que cada 1000 años desaparece un 20% del vocabulario básico de un idioma[19], pero esto es obviamente una generalización muy aproximada), y además, esta tasa de cambio no solamente ha variado en el tiempo, sino que además, ciertas palabras cambian con más facilidad que otras. Afortunadamente, en escalas de tiempo medianamente largas (de más de cincuenta años), las tasas de cambio parecen ser bastante constantes; sólo en escalas más cortas las tasas de cambio suelen variar considerablemente[20].
Varias refinaciones metodológicas han sido introducidas en la glotocronología, tomando en cuenta la irregularidad en las tasas de cambio, los préstamos entre idiomas, y otros factores que pueden causar errores. Además, se ha desarrollado métodos automatizados para mejorar la objetividad del método[21].
Mediante estas técnicas, se ha establecido que, por ejemplo, el proto-indoeuropeo pudiera haber sido hablado hace unos 7000 años[22]. De la misma manera se ha determinado las edades de los proto-idiomas mencionadas anteriormente en este post.
Cómo cambian los idiomas
Entremos ahora un poco en el mundo de la lingüística para ver cómo cambian los idiomas – aunque, obviamente, sin entrar en gran detalle, ya que para eso existen los libros de texto especializados[23].
Los cambios que ocurren en los idiomas a lo largo del tiempo son de distintos tipos:
- Fonéticos: cambia la pronunciación (y la manera de escribir) de las palabras.
- Lexicales: entran nuevas palabras y expresiones en el idioma, mientras que palabras existentes caen en desuso o cambian de significado.
- Gramaticales: cambia la manera en la cual se unen elementos de significado para formar unidades de significado más grandes (abajo veremos qué quiere decir esto).
Consideremos pues estas tres categorías de cambios. Aunque estos cambios ocurren en todos los idiomas, los ejemplos que mencionaré a continuación se referirán principalmente a la lengua castellana. Muchos de estos ejemplos fueron tomados de Pharies (2007) [24].
Cambios fonológicos
La fonología se refiere a la pronunciación de las palabras. Esta puede cambiar de muchas maneras. Algunos ejemplos del castellano son los siguientes:
- Lenición (suavización de sonidos): la tendencia de cambiar sonidos fuertes, o sea sonoros (por ejemplo los sonidos /a/, /e/ y /o/[25]) en sonidos suaves, o sea sordos (por ejemplo los sonidos /p/ o /h/). Este fenómeno ha sido común en el castellano; si comparamos palabras castellanas con las latinas de las cuales fueron derivadas, se ven claramente:
- Cambio F → H: ferrum → hierro; filium → hijo; formosum → hermoso. La letra H ha perdido su sonido: esto es un caso de suavización extrema.
- Diptongización de O y E (si están enfatizadas): hortus → huerta; porta → puerta; bene → bien; petra → piedra.
- Cambio C (/k/) → G o /θ/[26]: dicere → decir; facere → hacer; facio → hago; focus → fuego.
- Cambio CT → CH: factum → hecho; octo → ocho.
- Pérdida de letras: esta puede ocurrir al inicio, al final o dentro de palabras. Si ocurre dentro de una palabra, se habla de síncope (o síncopa). Ejemplos de síncope en la transición del latín al castellano son:
- opera → obra; littera → letra; digitum → dedo; hodie → hoy; computare → contar; hominem → hombre.
También ha ocurrido una importante pérdida de letras al final de las palabras (lo que se llama apócope). En el latín, las letras S y especialmente M al final de las palabras, utilizadas para marcar los casos nominativos y acusativos, se suavizaron en el tiempo y al final desaparecieron[27]. Los sustantivos castellanos provenientes del latín, son derivados del acusativo, con la letra M desaparecida. Aparte del ejemplo hominem → hombre arriba mencionado, he aquí unos más:
- patrem → padre; matrem → madre; noctem → noche; civitatem → ciudad. Se nota además la suavización de la T en los primeros dos ejemplos.
Cambios lexicales
Los cambios lexicales se refieren a la entrada de nuevas palabras y expresiones en el idioma, mientras que palabras existentes caen en desuso o cambian de significado (estos últimos se llaman cambios semánticos).
Todos los idiomas tienen palabras cuyos orígenes no se remontan al idioma ancestral, sino que son innovaciones, o palabras copiadas de otros idiomas. Generalmente se copian palabras de otros idiomas si se requiere dar un nombre a algo importado que antes no se conocía – por ejemplo la palabra futbol, importada de la Inglaterra. Por otro lado, también ocurre el copiado de palabras para conceptos que ya tenían nombre (por ejemplo, el copiado desde el inglés de las palabras oeste y este, en lugar de utilizar las palabras perfectamente adecuadas occidente y oriente); esto a menudo se debe a que la palabra importada es considerada como de más alto nivel social, o más fashion (para utilizar otra palabra importada).
En el caso del castellano, hubo varios idiomas que dejaron sus huellas en el vocabulario. Aparte de las palabras que se tomaron del inglés, las hay de origen francés: por ejemplo, moqueta y ordenador; y del Nuevo Mundo llegaron palabras como patata, maís, chocolate y tomate; etcétera. Pero el idioma del cual más palabras se tomaron, es el árabe. Se calcula que un 8% de los vocablos castellanos vienen de este idioma[28].
Muchas de las palabras de origen árabe se identifican fácilmente como tal: empiezan por “al” o “as”, siendo este el artículo, que en árabe se escribe pegado al sustantivo (as es la versión del artículo que se utiliza en árabe cuando la primera letra del sustantivo es una “s”). Pero cuidado: no todas las palabras castellanas que empiezan por “al” o “as” son de origen árabe, y asimismo, hay unas cuantas palabras de origen árabe que empiezan por otra letra.
Cientos de palabras castellanas son de origen árabe. He aquí algunas[29]:
aceite: de az-zayt = aceite.
albahaca: de habaqah.
albóndiga: de al-bunduqa = pelota, bola.
alcachofa: de al-ẖarshoof = alcachofa.
alcalde: de al-qadi = juez.
alcohol: de al-kuhul = un polvo utilizado para maquillaje.
algodón: de al-qúţun = el algodón.
almacén: de al-majzan o makhzan = el depósito.
almohada: de al-makhada = la almohada.
azúcar: de as-sukkar = el azúcar.
azul: de lazaward.
bellota: de balluta = bellota.
escabeche: de as-sukbaj. Originalmente del persa Sekba.
he (como en he aquí): de haa.
jabalí: de jebeli = de la montaña. Posiblemente originalmente khanzeer jebelí = cerdo de montaña.
jarra: de garrah = jarra.
ojalá: de law šha’allāh = si Dios quiere.
¡olé!: probablemente de wa-llah = por Alá!
rincón: del árabe andalús rukan, derivado del árabe clásico rukn.
sandía: de sindiya = proveniente de Sindh (provincia de la India).
taza: de tasa.
zumo: de zum.
Además existen varias expresiones en castellano cuyo significado (mas no las palabras en sí) parece haber sido copiado del árabe. Un ejemplo es la expresión si Dios quiere, que Dios guarde o bendito sea Dios, que es la traducción del árabe in sha’Allah = si Alá quiere.
Sirva esta pequeña lista para recordarnos que, a veces sin darnos cuenta, estamos utilizando a diario palabras de origen árabe!
Cambios gramaticales
La gramática se refiere a la manera en la cual se unen elementos de significado para formar unidades de significado más grandes. Tradicionalmente, la gramática se divide en la morfología (la manera en la cual palabras se componen de elementos gramaticales, es decir morfemas) y la sintaxis (la manera en la cual se unen las palabras en una frase).
Es posible clasificar los idiomas del mundo según su morfología y según la sintaxis. Estas clasificaciones son tipológicas, no genéticas: se agrupan los idiomas según ciertos criterios, sin que los idiomas en un grupo estén necesariamente relacionados genéticamente entre sí. Una clasificación con criterios de sintaxis es la que considera el orden del sustantivo (S), verbo (V) y objeto (O). La mayoría de idiomas, especialmente los occidentales, son del tipo SVO, o sea, construyen frases del tipo “la vaca come pasto”. Muchos otros idiomas, por ejemplo del sureste asiático, son del tipo SOV. Muy pocos idiomas son del tipo VSO[30]. Las familias de idiomas tienden a tener su propio orden, que puede ser distinto al de otras familias, lo que indica que el orden es un elemento lingüístico sujeto a evolución cultural – no es algo universal, tal como, entre otros, propuso Chomsky[31] (ver mi post de 19 mayo 2015).
Una clasificación que nos interesa más, es de naturaleza morfológica. En esta, se considera cuánta información gramatical contiene cada palabra. Tradicionalmente se distinguen en este sentido tres categorías de idiomas:
- Idiomas aislantes (o analíticos): idiomas en los cuales, en el caso extremo, cada palabra contiene un solo elemento de información gramatical[32]. Muchos idiomas del sureste asiático son aislantes. En el chino, por ejemplo, la frase “ellos hacen sus deberes” se dice “tā men zài zuò zuòyè”, o sea “él – palabra indicando plural – palabra indicando el presente – hacer – deberes”. Mientras que la palabra “ellos” indica a la vez que se refiere a la tercera persona y al plural, en chino hay una palabra para cada una de estas informaciones gramaticales. Igual para el verbo “hacen”: en chino se indica mediante una palabra separada que el verbo se refiere al presente.
- Idiomas aglutinantes: idiomas en que las palabras contienen múltiples elementos de información gramatical, en los cuales cada elemento tiende a dar un solo dato gramatical. En casos extremos, una sola palabra puede contener toda la información de una frase entera. El finés, el turco y el japonés son algunos de los idiomas aglutinantes. En el japonés, por ejemplo, la frase “Hiroshi tabetakunakatta” quiere decir “Hiroshi no quiso comer”; en esta frase, el verbo consiste en los siguientes elementos de información gramatical: tabe/ta/ku/nakatta – añadiendo al verbo “comer” información de deseo, negación, y el tiempo pasado[33].
- Idiomas flexivos (o fusionantes): idiomas en que las palabras contienen múltiples elementos de información gramatical, pero en los cuales cada elemento tiende a dar múltiples datos gramaticales[34]. Un ejemplo extremo de un idioma fusional es el latín: en la frase “Marcus amat Sophiam”, o sea “Marco quiere a Sofía”, el elemento gramatical “-us” indica que Marcus es masculino, singular y el sujeto de la frase – o sea, un solo elemento proporciona tres datos gramaticales.
Dentro de estas tres categorías existen obviamente gradaciones: entre los idiomas aislantes hay algunos que son más aislantes que otros, etcétera.
Volvamos ahora al tema de este post, la evolución del idioma. La estructura gramatical de un idioma no permanece congelada en el tiempo: así como cambian las palabras, también cambian las estructuras gramaticales. Existe una tendencia para idiomas aislantes de volverse aglutinantes, para idiomas aglutinantes de volverse flexivos, y para idiomas flexivos de volverse aislantes. Es un ciclo de aumento y reducción de la complejidad.
El castellano, así como la mayoría de los idiomas indoeuropeos, está en esta última transición: la del latín (que como vimos es un idioma extremamente flexivo) a una tipología aislante. El castellano se encuentra más o menos a medio camino, puesto que por un lado perdió las declinaciones típicas del latín (así que la sola palabra “Marcos” en el ejemplo de arriba ya no nos cuenta si es él quien quiere, o si es el querido), pero los verbos siguen teniendo elementos gramaticales llenos de información: en la palabra “habló”, por ejemplo, el elemento “-ó” nos indica que la palabra es un verbo que se refiere a la tercera persona, singular, y que la acción ocurrió en el pasado.
El inglés, por otro lado, se encuentra en una posición más adelantada en la transición a un idioma aislante. En inglés, para traducir la palabra “habló” se requieren tres palabras: “he has spoken” o “she has spoken”. En este sentido se puede afirmar que el inglés es gramaticalmente más simple que el español, que a su vez es más simple que el latín.
Simplificación
En términos generales, es más común la simplificación de un idioma que lo opuesto. Esto se debe, en gran medida, a factores neurofisiológicos: cuando una persona tiene que procesar un elemento gramatical complejo, la actividad cerebral es mayor que cuando procesa un elemento gramatical simple. Por lo tanto, puede ser una tendencia natural del individuo preferir construcciones simples y por ende, fomentar una simplificación del idioma[35].
El proceso de simplificación no es continuo: mientras que una regla gramatical al final de un proceso de simplificación puede ser bastante más simple que al inicio del proceso, puede haberse dados fases intermedias más complejas. Al parecer, un sistema gramatical complejo no puede ser desmantelado de un golpe: requiere que sea cambiado paso por paso[36].
Conclusión
Hemos hablado un poco del árbol genealógico de los idiomas, enfocándonos en los europeos. Vimos cómo, al comparar ciertas características de los idiomas, podemos sacar algunas conclusiones acerca de cómo agrupar los idiomas y determinar cuáles idiomas tienen ancestros comunes, y cuáles no. A veces se puede identificar el ancestro común (el “proto-idioma”), por ejemplo el latín siendo el ancestro de los idiomas románicos tales como el castellano. Pero a menudo lo máximo que se puede hacer es identificar ciertas características que debe haber tenido el proto-idioma, sin llegar a determinar quiénes hablaron ese idioma, o cuándo se habló.
La metodología para elaborar tal árbol genealógico es parecida a la que se utiliza para le determinación de las relaciones entre especies biológicas, y de hecho los idiomas son parecidos a las especies, puesto que ambos pueden cambiar, dar origen a nuevos idiomas/especies, y desaparecer.
De las muchas maneras en las cuales pueden cambiar los idiomas, vimos algunos ejemplos. Los cambios pueden ser fonéticos, lexicales y gramaticales. Dentro de los cambios gramaticales, es notoria la tendencia de simplificación: idiomas flexivos que con el tiempo se vuelven más aislantes.
En el próximo post nos enfocaremos en la pregunta de por qué cambian los idiomas. ¿Cuáles son las fuerzas que hacen que un idioma cambie? ¿Qué es lo que pone en marcha este aspecto de la evolución cultural?
Este post se basa en dos posts que publiqué en mi blog, ahora cerrado, “Los tiempos del cambio”.
Nota: la foto en el encabezado del post muestra la portada de la primera edición de la primera parte de El ingenioso hidalgo don Quixote de la Mancha, libro de Miguel de Cervantes. Madrid: Juan de la Cuesta; 1605. Fuente: https://es.wikipedia.org/wiki/Don_Quijote_de_la_Mancha.
[1] Atkinson, Q.D. y Gray, R.D., 2005. Curious parallels and curious connections – Phylogenetic thinking in biology and historical linguistics. Systematic Biology, 54 (4), 513-526.
[2] Atkinson y Gray, 2005. Ver nota 1.
[3] Crowley, T., 1992/1997. An introduction to historical linguistics. Oxford University Press. En este post, mucho de lo escrito proviene de este último libro, a no ser que se haga referencia a otra publicación.
[4] Este ejemplo es bastante famoso. Yo lo tomé, con modificaciones, de: Janson, T., 2002. Speak. A short history of languages. Oxford University Press.
[5] Gray, R.D. y Atkinson, Q.D., 2003. Language-tree divergence times support the Anatolian theory of Indo-European origin. Nature, 426, 435-439. www.nature.com/nature/journal/v426/n6965/full/nature02029.html. Ver también: https://es.wikipedia.org/wiki/Lenguas_indoeuropeas.
[6] Anthony, D.W., 2007. The horse, the wheel, and language. How Bronze-age riders from the Eurasian steppes shaped the modern world. Princeton University Press. Haak, W. y otros, 2015. Massive migration from the steppe is a source for Indo-European languages in Europe. Nature, 522, 207-211. www.nature.com/nature/journal/v522/n7555/abs/nature14317.html. Chang, W., Cathcart, C., Hall, D. y Garrett, A., 2015. Ancestry-constrained phylogenetic analysis supports the Indo-European steppe hypothesis. Language, 91 (1), 194-244. www.linguisticsociety.org/sites/default/files/07_91.1Chang.pdf. Callaway, E., 2015. Language origin debate rekindled. Eurasian steppe gains ground as Indo-European birthplace. Nature, 518, 284-285. www.nature.com/polopoly_fs/1.16935!/menu/main/topColumns/topLeftColumn/pdf/518284a.pdf.
[7] Gray y Atkinson, 2003. Ver nota 5. Bouckaert, R. y otros, 2012. Mapping the origins and expansion of the Indo-European language family. Science, 337, 957-960. www.sciencemag.org/content/337/6097/957.full.pdf.
[8] Balter, M., 2016. Language wars. Scientific American, mayo 2016, 60-65. www.ScientificAmerican.com. Ver también: www.sciencemag.org/news/2015/02/mysterious-indo-european-homeland-may-have-been-steppes-ukraine-and-russia.
[9] Ver https://es.wikipedia.org/wiki/Macrofamilia_nostr%C3%A1tica.
[10] Ruhlen, M., 1992. An overview of genetic classification. En: J.A. Hawkins y M. Gell-Mann (eds.), The evolution of human languages; pág. 159-189. Santa Fe Institute, Studies in the Sciences of Complexity, Proceedings Volume XI. Addison-Wesley. Ver también: https://es.wikipedia.org/wiki/Lenguas_uralo-siberianas.
[11] Dediu, D. y Levinson, S.C., 2012. Abstract profiles of structural stability point to universal tendencies, family-specific factors, and ancient connections between languages. PLoS ONE, 7(9), e45198. http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0045198.
[12] Dunn, M., Terrill, A., Reesink, G., Foley, R.A. y Levinson, S.C., 2005. Structural phylogenetics and the reconstruction of ancient language history. Science, 309, 2072-2075. http://science.sciencemag.org/content/sci/309/5743/2072.full.pdf.
[13] Greenhill, S.J., Wu, C.-H., Hua, X., Dunn, M., Levinson, S.C. y Gray, R.D., 2017. Evolutionary dynamics of language systems. Proceedings of the National Academy of Sciences, 114 (42), E8822–E8829. www.pnas.org/content/114/42/E8822.full.pdf.
[14] Dunbar, R.I.M., 2003. The origin and subsequent evolution of language. En: M.H. Christiansen & S. Kirby (eds.): Language evolution. Oxford University Press. Pág. 219-234.
[15] Pawlowitsch, C., Mertikopoulos, P. y Ritt, N., 2011. Neutral stability, drift, and the diversification of languages. Journal of Theoretical Biology, 287, 1-12. www.sciencedirect.com/science/article/pii/S0022519311003493.
[16] Ver https://es.wikipedia.org/wiki/Idioma_protoindoeuropeo.
[17] Ver por ejemplo: https://anthropology.net/2017/04/23/an-auditory-reconstruction-of-the-6000-year-old-proto-indo-european-language.
[18] Dediu, D. y Christiansen, M.H., 2016. Language evolution: constraints and opportunities from modern genetics. En: D. Kimbrough Oller, R. Dale y U. Griebel (eds.) New Frontiers in Language Evolution and Development, pág. 361-370. Wiley, Topics in Cognitive Science, Vol. 8. http://onlinelibrary.wiley.com/doi/10.1111/tops.12195/full.
[19] Swadesh, M., 1955. Towards greater accuracy in lexicostatistic dating. International Journal of American Linguistics, 21, 121-137. www.journals.uchicago.edu/doi/abs/10.1086/464321.
[20] Bochkarev, V., Solovyev, V. y Wichmann, S., 2014. Universals versus historical contingencies in lexical evolution. Journal of the Royal Society Interface, 11, 20140841. http://rsif.royalsocietypublishing.org/content/11/101/20140841.
[21] Holman, E.W. y otros, 2011. Automated dating of the world’s language families based on lexical similarity. Current Anthropology, 52, (6), 841-875. http://www.jstor.org/stable/10.1086/662127.
[22] Ver https://es.wikipedia.org/wiki/Glotocronolog%C3%ADa.
[23] Ver por ejemplo: Chambers, J.K., Trudgill, P. y Schilling-Estes, N. (editores), 2004. The handbook of language variation and change. Wiley-Blackwell. Labov, W., 1994. Principles of linguistic change. Wiley-Blackwell. Crowley, T., 1992/1997. An introduction to historical linguistics. Oxford University Press.
[24] Pharies, D.A., 2007. Breve historia de la lengua española. The University of Chicago Press. Otros libros en castellano sobre la historia del castellano incluyen dos con el mismo título, “Historia de la lengua española”: uno por Rafael Lapesa (Editorial Gredos), otro por Rafael Cano (Editorial Ariel).
[25] Esta manera de escribir, /a/, se usa para indicar que se está hablando del sonido “a”, no de la letra “a”.
[26] El símbolo θ se refiere a la pronunciación española de la C en “decir”. En América latina, esta C se pronuncia más como /s/.
[27] Ver http://en.wikipedia.org/wiki/Vulgar_Latin.
[28] Ver http://en.wikipedia.org/wiki/Spanish_vocabulary.
[29] Ver http://en.wikipedia.org/wiki/Arabic_influence_on_the_Spanish_language.
[30] Dryer, M.S., 1992. The Greenbergian word order correlations. Language, 68 (1), 81-138. https://muse.jhu.edu/article/452860/pdf.
[31] Dunn, M., Greenhill, S.J., Levinson, S.C. y Gray, R.D., 2011. Evolved structure of language shows lineage-specific trends in word-order universals. Nature, 473 (7345), 79-82. www.nature.com/nature/journal/v473/n7345/full/nature09923.html.
[32] Ver https://es.wikipedia.org/wiki/Lengua_aislante.
[33] Ver https://es.wikipedia.org/wiki/Lengua_aglutinante; http://www.sil.org/linguistics/GlossaryOfLinguisticTerms/WhatIsAnAgglutinativeLanguage.htm.
[34] Ver https://es.wikipedia.org/wiki/Lengua_fusionante.
[35] Bickel, B., Witzlack-Makarevich, A., Choudhary, K.K., Schlesewsky, M. y Bornkessel-Schlesewsky, I., 2015. The neurophysiology of language processing shapes the evolution of grammar: evidence from case marking. PLOS ONE, http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0132819.
[36] Kiparsky, P., 2010. Dvandvas, blocking, and the associative: the bumpy ride from phrase to word. Language, 86 (2), 302-331. www.jstor.org/stable/40666322 Kiparsky, P., 2015. New perspectives in historical linguistics. En Claire Bowern (ed.) The Routledge Handbook of Historical Linguistics. https://web.stanford.edu/~kiparsky/Papers/handbook.pdf.
